Bot. Bull. Acad. Sin. (2001) 42: 243-250
Lin et al. Genetic organization of ZYMV Taiwan isolate
Complete genome sequence and genetic organization of a Taiwan isolate of Zucchini yellow mosaic virus
Shih-Shun Lin1, Roger F. Hou1, and Shyi-Dong Yeh2,*
1Graduate Institute of Agricultural Biotechnology and 2Department of Plant Pathology, National Chung Hsing University, Taichung, Taiwan 402, Republic of China
(Received March 6, 2001; Accepted May 28, 2001)
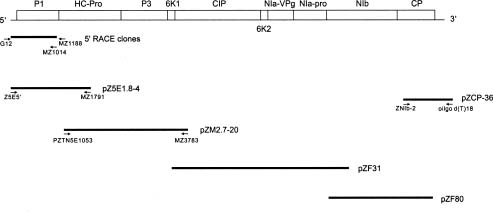
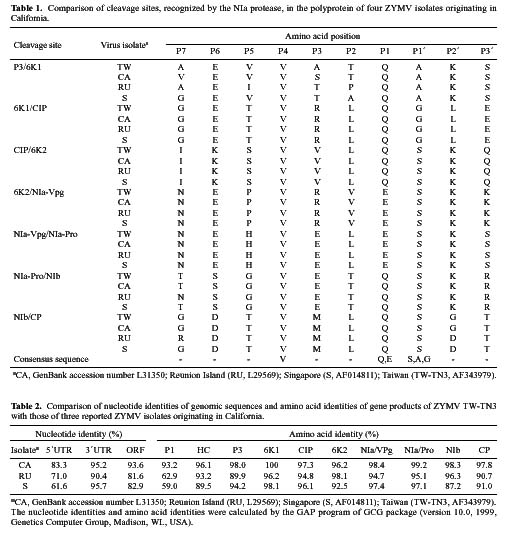
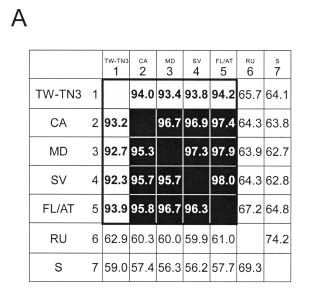
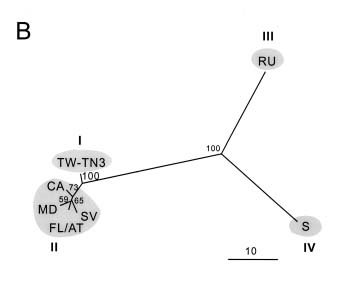
Abstract. The complete nucleotide sequence of the RNA genome of a Taiwan isolate of Zucchini yellow mosaic virus (ZYMV TW-TN3) was determined from five overlapping cDNA clones 9591 nucleotides in length excluding the poly (A) tail. Computer analysis of the sequence revealed a large open reading frame (ORF) that encodes a polyprotein of 3080 amino acids. Comparison of the gene products of TW-TN3 with those of the reported California (CA), Reunion Island (RU), and Singapore (S) isolates of ZYMV revealed that P1 protein is most variable, with amino acid identities of 59.0-93.2%. The 5´ untranslated region (UTR) of TW-TN3 shares 61.6-83.3% nucleotide identities, and the 3´ UTR shares 90.4-95.7% nucleotide identities, with those of the other isolates. A phylogenetic tree derived from the sequences of P1 proteins of TW-TN3 and the other six reported ZYMV isolates revealed four major genotypes. TW-TN3 was classified in genotype I, and US isolates were in genotype II. The Reunion Island and Singapore isolates were separated into genotypes III and IV, respectively. The distance relationships of P1 protein of genotype I were closer to genotype II, indicating that the Taiwan and US isolates may evolve from the same ancestor. Analyses on the cleavage sites of the C-terminal halves of the polyproteins of TW-TN3, CA, RU, and S isolates revealed that NIa protease cleaves at Q-S, and E-S dipeptide sequences, with a consensus sequence of V-x-x-(Q, E)/(S, A, G). The genetic organization of TW-TN3 was concluded as Vpg/5´ leader/P1 (36 kDa)/HC Pro (52 kDa)/P3 (40 kDa)/6K1 (6 kDa)/CIP (71 kDa)/6K2 (6 kDa)/NIa-Vpg (22 kDa)/NIa-Pro (27 kDa)/NIb (60 kDa)/CP (31 kDa)/3´ UTR-poly(A) tract.
Keywords: Genetic organization; Genome sequence; ZYMV isolates.
Introduction
Zucchini yellow mosaic virus (ZYMV), a member of the genus Potyvirus in the family Potyviridae, was first reported in Italy in 1973 (Lisa et al., 1981) and was subsequently found causing devastating epidemics in commercial cucurbits worldwide (Lisa and Lecoq, 1984). Symptoms include mosaic, yellowing, shoestring, and distortion on leaves; stunting in plant growth; and deformation of fruits. A Taiwan isolate, designated ZYMV TW-TN3, was collected from diseased sponge gourd (Luffa cylindrica Roem.) from Tainan, Taiwan, in 1993 (Lin et al., 1998). Similar to other potyviruses, TW-TN3 RNA was presumed coding a single large polyprotein that undergoes proteolytic processing by virus-encoded proteases to yield several mature gene products (Shukla et al., 1994).
The complete nucleotide sequences of the RNA genomes of three ZYMV isolates, ZYMV CA (California isolate) (Wisler et al., 1995), ZYMV RU (Reunion Island isolate) (Wisler et al., 1995) and ZYMV S (Singapore isolate) (Lee and Wong, 1998) have previously been
reported. Based on the degrees of coat protein (CP) homology, these three ZYMV isolates were classified in genotypes II, III, and VI, respectively (Lin et al., 2000). However, the TW-TN3 isolate and most of Taiwan ZYMV isolates were placed in genotype I (Lin et al., 2000). Thus, elucidation of the genomic sequence of TW-TN3 would further understanding of its relationships with other genotypes.
In this study, the complete nucleotide sequence of TW-TN3 was determined and compared with those of the CA, RU, and S isolates. Moreover, since sequence information for the P1 proteins of the additional three ZYMV US isolates (SV, MD, and FL/AT) was also available (Wisler et al., 1995), phylogenetic analysis based on P1 proteins was performed to investigate the evolutionary relationships among the TW-TN3 and the other six ZYMV isolates reported.
Materials and Methods
Virus Purification and RNA Extraction
A typical isolate of ZYMV TW-TN3 was isolated from naturally infected sponge gourd grown in Tainan, Taiwan, (Lin et al., 1998), and propagated in zucchini squash (Cucurbita pepo L. var. Zucchini) under greenhouse conditions. Viral particles were purified by PEG precipita
3The GenBank accession number for the sequence data reported in this paper is AF343979.
*Corresponding author. Tel: 886-4-22877021; Fax: 886-4-22877585; E-mail: sdyeh@nchu.edu.tw