28
Botanical Studies, Vol. 51, 2010
methionine-rich domain is the most conserved (Chen
and Vierling, 1991; Vierling, 1991; Waters, 1995).
Maintenance of a robust photosynthetic system under heavy metal contamination is reported to be relevant to CPsHSPs (Heckathorn et al" 2004). Recently, the evolutionary and ecological roles of HSPs have been explored (S0rensen et al., 2003). Among eight closely related species from the genus Ceanothus, the expression of C PsHS P was found to be associated with the photosynthetic thermal tolerance (Knight and Ackerly, 2001). Interestingly, Barua et al. (2003) reported that polymorphism in the expression levels of CPsHSPs has played a key role in the population fitness of Chenopodium album. Subfunctionalization of CPsHSPs has been investigated in bentgrass (Agrostis stolonifera) (Wang and Luthe, 2003). Recently, extensive silent mutations have been documented in nucleotide sequences of the animal nucleophosmin/nucleoplasmin types of chaperones, indicating strong purifying selection at the protein level (Eirin-Lopez et al., 2006). However, the population evolutionary dynamics of CPsHSP genes have not been investigated in plants; therefore, it is unclear whether balancing or purifying selection is the predominant force shaping the molecular evolution of CPsHSP genes in plant populations.
Previously, two copies of CPsHSP genes were identified in the genus Machilus (Wu et al., 2007). These two copies of CPsHSPs displayed high levels of conservation in the amino acid sequences of the methionine-rich domain but were highly diversified in the region of the ACD. Machilus (Lauraceae) are evergreen trees or shrubs which consist of about 100 species distributed mainly in tropical and subtropical areas of Asia (Liu et al., 1994). Machilus kusanoi Hayata is widely distributed but mainly i n the lowland river regions in Taiwa n. Int erspecific comparisons can identify differences in the evolutionary history of loci between species, but might not reveal the changes that are shaping the evolutionary dynamics of each locus throughout the adaptive landscape. The recent copy is postulated to have evolved under positive selection for different chaperonin activities in comparison with the ancient copy due to a hydrophobicity shift in the methionine-rich domain and the ACD domain of the CPsHSP (Wu et al., 2007). The hydrophobicity of amino acid residues in the ACD is thought to be important for polypeptide binding (Sharma et al., 1998). sHSPs usually form large oligomeric complexes and provide a means to rapidly expose subunits, a process which offers hydrophobic surfaces for the binding of misfolded denatured substrate proteins, thereby protecting them from inappropriate aggregation (Ganea, 2001; Sun et al., 2002).
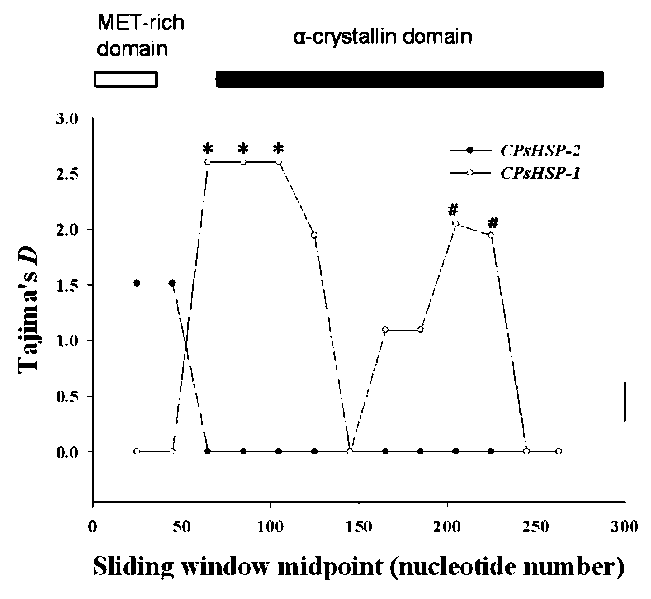
The frequency of specific alleles and/or phenotypes in a broad geographic region has long been used to infer plant adaptation to climatic variations in an array of taxa. In this study, we present an analysis of DNA sequence variations
across the ACD of the CPsHSP-1 and CPsHSP-2 loci of
Machilus kusanoi using samples collected from across its distributional range, in an attempt to address several
questions related to the evolutionary history of CPsHSP protein polymorphism. By using a nucleotide sequence approach in randomly selected individuals, we hope to determine whether there are amino acid replacement polymorphisms at the nucleotide level within and among populations. Additionally, we were interested in whether patterns of nucleotide diversity at CPsHSP are consistent with balancing selection.
materials and methods
Plant materials and DNA purification
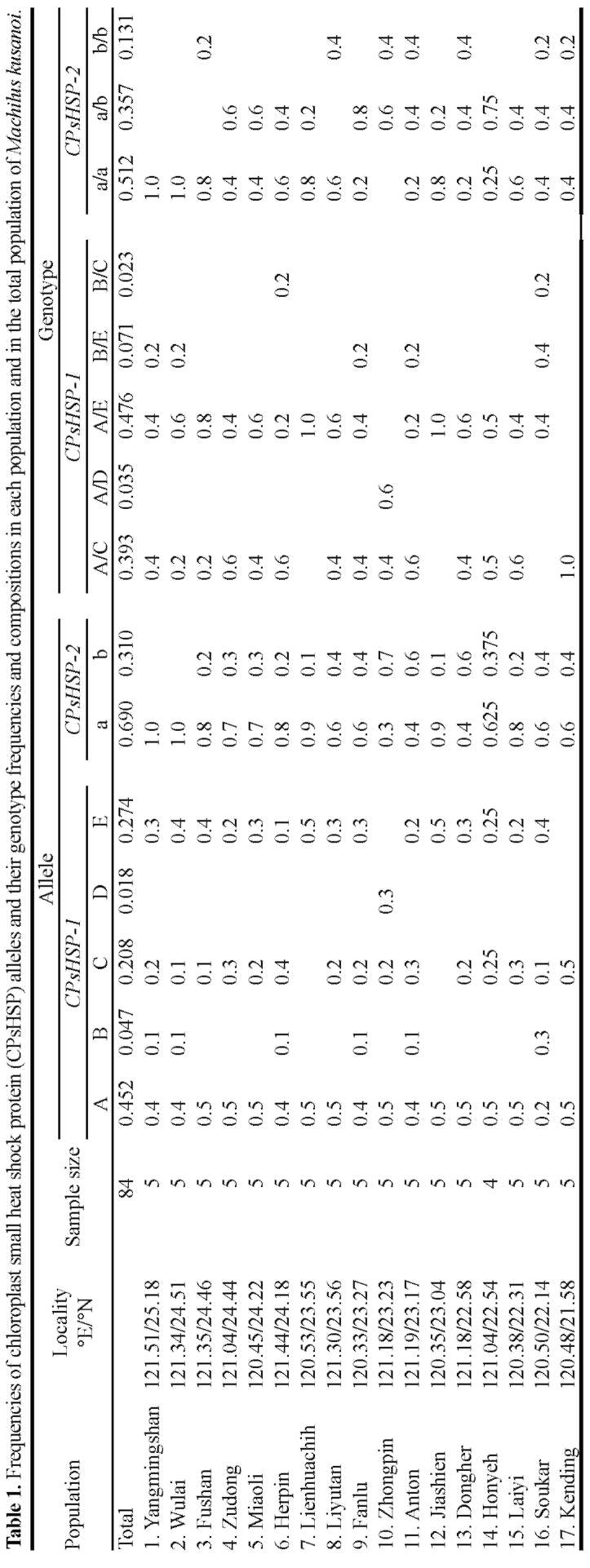
Sequence variation was surveyed from DNA samples of 84 individuals randomly collected from 17 populations in Taiwan encompassing the entire distributional range of Machilus kusanoi. The population code, sample size, longitude, and latitude of each population within Taiwan are shown in Table 1, and collection sites are depicted in Figure 1. Total DNA was extracted from ground-up leaf-powder according to a cetyltrimethyl ammonium bromide
(CTAB) procedure (Doyle and Doyle, 1987). DNA was
precipitated with ethanol and, after washing with 70% ethanol, was dissolved in 200 fiL TE buffer (pH 8.0) and
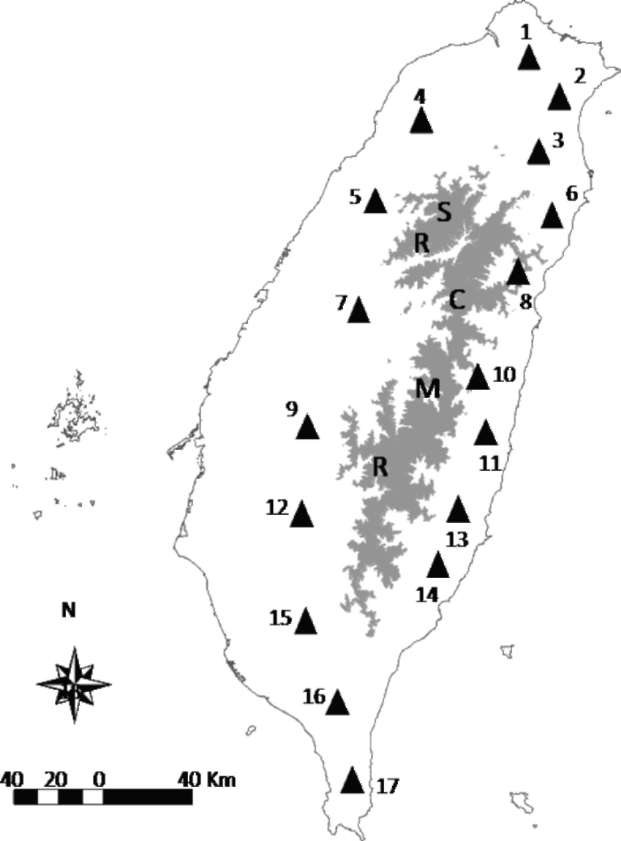
Figure 1. Map of Taiwan showing the sampling sites of Machilus kusanoi. The shaded area indicates the Shueshan Range (SR) and the Central Mountain Range (CMR). The longitude and latitude of each population are listed in Table 1. The number designates the population code and corresponds to that which appears in Tables 1 and 3.